MySQL_库和表的使用(部分未完
库和表的使用操作小记
记录的是基础用法,有很多细节省略了,详细请看课件或者完整笔记
MySQL的SQL语句分为以下三类
DDL 【数据定义语句】
用来维护存储数据的整体结构,比如库和表的创建、修改、删除、备份与还原、查看
代表命令
create,alter,drop,source,showDML【数据操纵语句】
用来操作表中的具体数据,比如插入数据、查询数据、删除数据
代表命令
insert,select,delete,updateDLC【数据控制语句】
负责权限管理和事务
代表命令
grant,revoke,commit
登录mysql
有两种方式:
指明端口

不指明端口,使用默认的
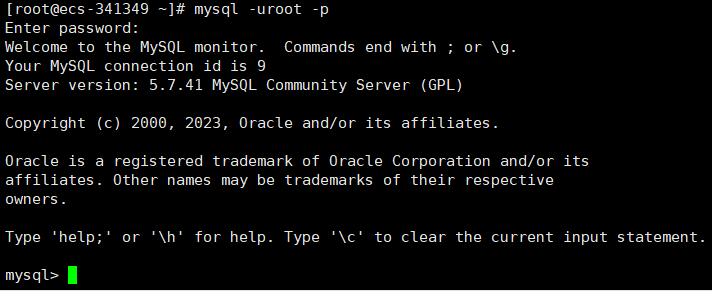
-p的作用是不显式地输入密码,我并没有设置root账户的密码,直接按回车即可
-u和root之间可以有空格可以没有
DDL【数据定义语句】
查看mysql所有库
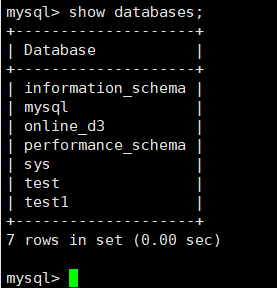
注意mysql语句要用分号结尾
创建库

或者“如果这个库不存在的话,就创建”(创建表的时候也一样):
注意,关于库、表的名称,最好使用反引号`` `括起来,这个符号是电脑esc键下面的键,半角状态打出
也可以不括起来,但是如果名称和mysql内部一些名称冲突的话,会报错

查看创建库的记录(查看库结构)
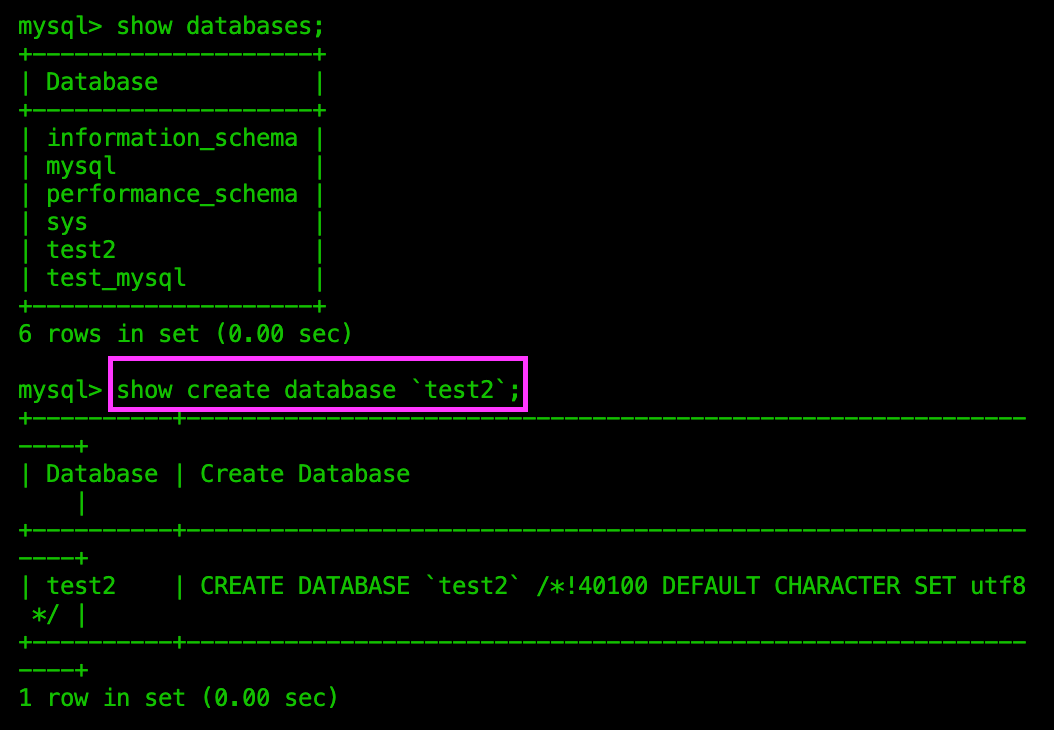
- 只能查看已创建的库
- 本质上是查看创建库的所有语句,这些语句保存在了一个文件中,这个文件可以用于库的备份(见另一篇文章)
删除库
进入/使用库
查看当前所在库

退出库
严格来说也不是退出,而是返回到最初的库

当然,是没有必要退出的,因为在其他数据库的时候,还是可以使用show databases;命令查看所有数据库,并使用use 数据库名;直接进入其他数据库
创建表
1 | create table 表名 ( |
最下面一行后面的内容可以省略

可以换行可以不换
换行更美观,但是换行之后之前输入的内容无法修改,所以写代码要准确
Sno、Sname、Sage之类的就是列属性,就是列名
Sno它们后面跟的是这一列数据的数据类型
comment是给这个列加备注,可以加可以不加
if not exists 可加可不加,意思是如果Student这个表之前不存在的话,就创建,存在的话就不创建,在前面的库的创建和删除中,以及在后面的表的删除中,也是可加可不加
查看表的属性

查看库中的所有表

查看创建表的记录(查看表结构)

- 只能查看已存在的表
- 本质上是打印出来创建表的时候执行的所有语句
省略长横线:

新增列(新增字段)
在SC表中的Cno列后面新增一列Grade
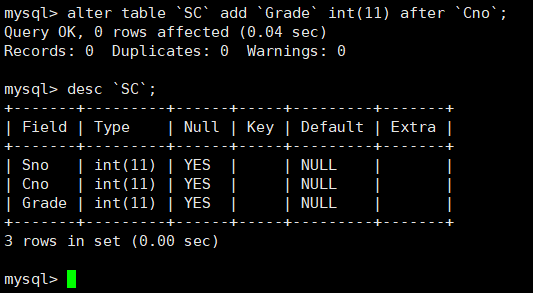
- 如果不加after,默认加在最后一列
- 新增一列之后,此列的数据默认为NULL
查看一下表结构,发现列信息被加入进去了:

新增列(字段)时设置默认数据填充
由于一般新增列的时候,默认该列的数据都为空NULL,但是有些场景需要指定默认数据
创建新列时设置默认填充数据:

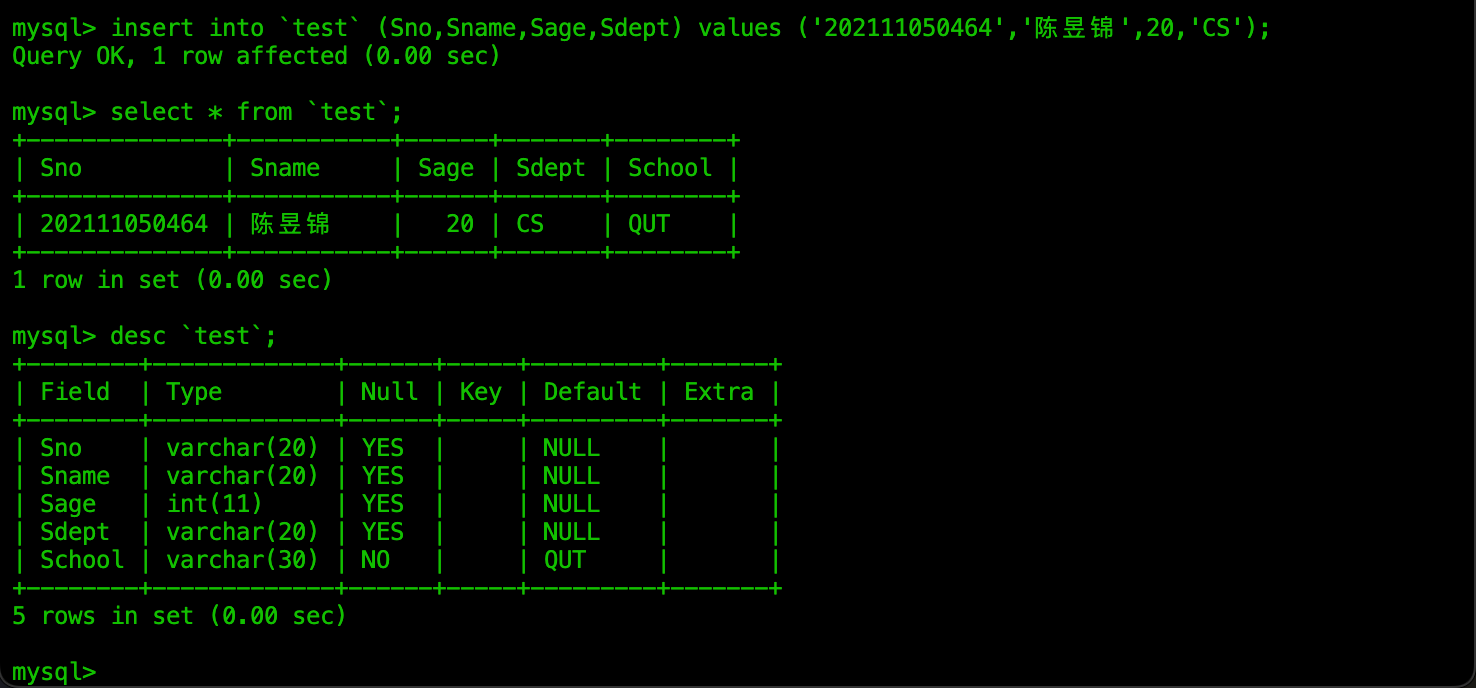
设置主键
主键用于标定一张表中一条数据的唯一性的的列。主键不为空、数据值不能重复,因此可以标定一条数据的唯一性。
一张表中只能有一个主键,但是主键可以是由一列构成,也可以由多列复合而成(复合主键),只要复合主键中并不是每一列的数据都是相同的,那么这个数据就是唯一的。
一般选择int类型字段作为主键(比如ID之类)
新建表时创建主键
方法一:在设置字段的时候设置上主键

方法二:在最后设置主键
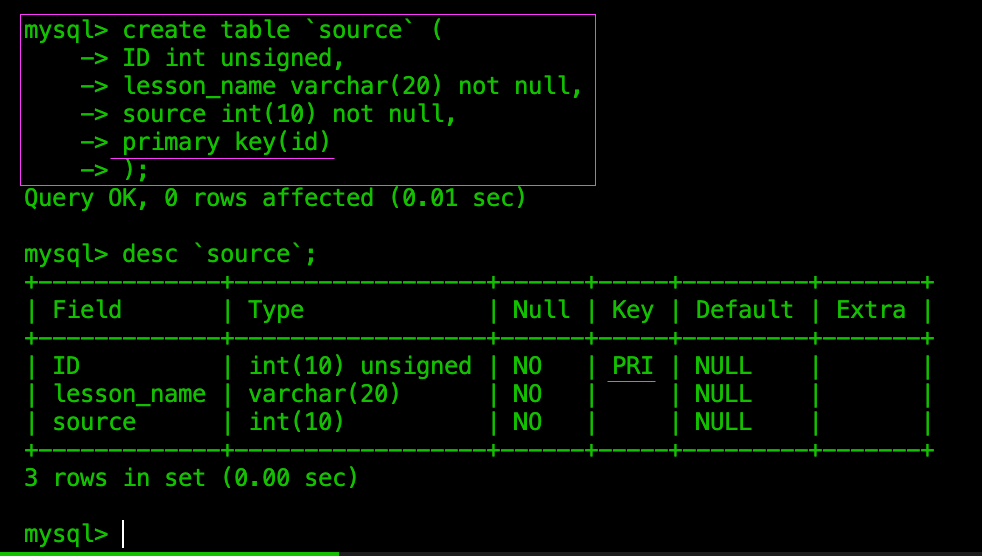
- 两种方式都会用到
- 主键本身就不能为空,因此可以省略
not null
取消主键

设置现有列(字段)为主键

在添加新字段时设置为主键
前提是表中没有主键

设置复合主键
创建新表时设置
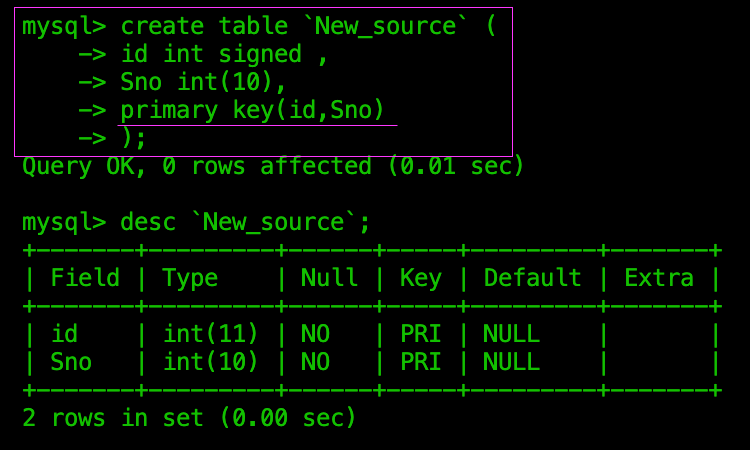
不能用第一种方式创建
会报错“定义了重复主键”

设置现有字段为复合主键
此前表中没有主键
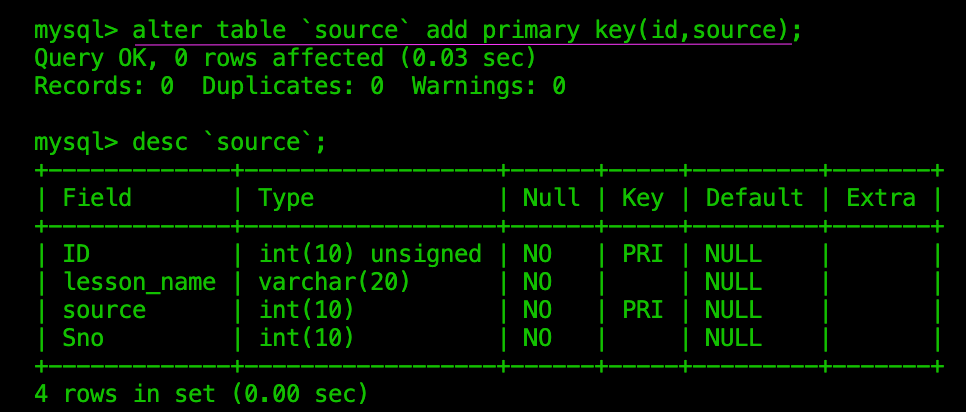
更多
关于主键、默认值(default)、唯一键、外键等SQL字段约束相关知识,在慕雪的寒舍-SQL字段约束
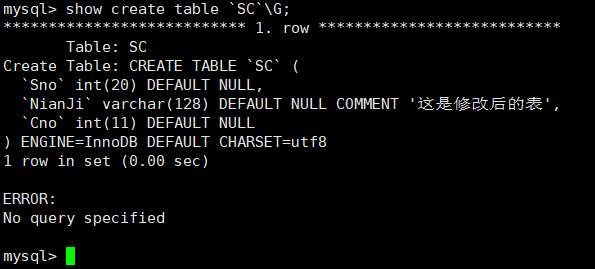
修改列的数据类型
将SC表中的Sno的数据类型由int(11)改为int(20)

查看一下表结构:

说明修改表的某一列是用新的列覆盖掉旧的列
将同类型缩小,要确保原数据不会溢出
不同类型之间转换的时候,要确保这两种数据之间是能双向转化的
修改列名
将表SC的Grade列改名为NianJi
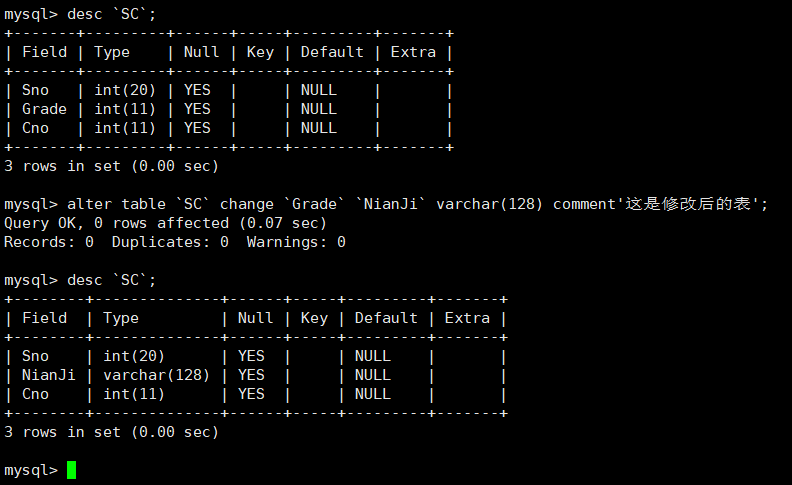
注意,在改列名的时候,必须还要重新指定该列的数据类型,可以保留原来的,也可以修改,但必须都要写出。
这里我顺便修改成新的数据类型,还可以加注释。
所以说修改列名是包含了修改修改数据类型的
修改列名使用change而不是rename
- rename留给了修改表名使用
- 修改列名的时候不只是修改了列名,还有加上该列的数据类型(无论是否更改),因此用change更合理
查看一下表结构:
删除列

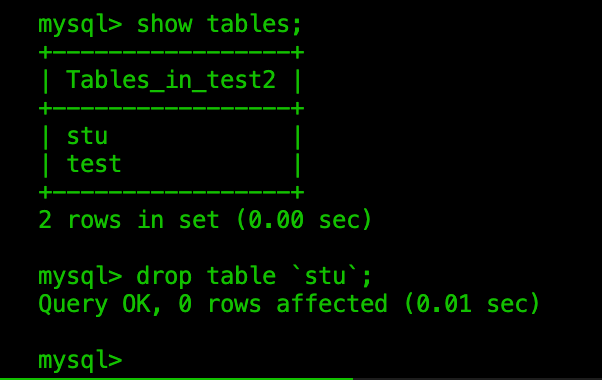
凡是涉及到删除的操作,都要慎重
如果表中只剩下一列,不能删除列了,只能删除整张表
删除表
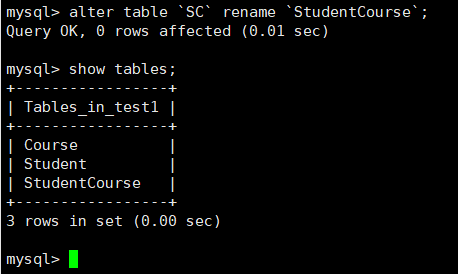
修改表名
数据库备份
https://blog.musnow.top/posts/2109090510/
备份命令在shell命令行进行
1 | mysqldump [-P端口号] -u用户名 -p密码 [-B] 数据库名 > 备份后的名称.bak.sql |
[ ]内的是可以省略的
-u和用户名、-p和密码之间可以加空格,可以不加
-B和数据库名之间必须有空格(如果-B没有省略的话)
端口号可能是3306,取决于数据库有没有指定端口
备份后的文件要具体到路径,否则认为当前工作路径(同其他shell命令一样)
eg1:mysqldump -uroot -p0295 test2 > ../test2.bak.sql备份到了父目录
eg2:mysqldump -P3306 -uroot -p0295 test2 > test2.bak.sql备份到了当前目录
可以多个数据库同时备份
1 | mysqldump [-P端口号] -u用户名 -p密码 [-B] 数据库1 数据库2 > 备份后的名称.bak.sql |
eg:mysqldump -uroot -p0295 -B test2 test_mysql > test.back.sql两个数据库备份到了一个备份文件上
也可以只进行数据库中表的备份
1 | mysqldump [-P端口号] -u用户名 -p密码 数据库名 表1 表2 > 备份后的名称.bak.sql |
备份表的时候不能加-B,因为-B是专用于数据库的,否则会把表名当成数据库名
eg:mysqldump -uroot -p0295 test2 test2_table1 > test_table1.back.sql
其他知识点详见置顶链接
还原命令在mysql中执行
1 | mysql> source 备份文件路径 |
eg:source /yj/test2.bak.sql
数据库中的内容和原来数据库中的内容是相同的
mysql备份的时候,会将里面的语句智能化简
MySQL通过system执行shell命令
eg:mysql> system clear执行清理屏幕功能
DDL命令操作表时要加table固定写法
比如alter, drop等等,后面都需要加table, 然后才能跟表名
而下面的DML在指定表名的时候不需要写table, 直接用表名就可以
这是因为DDL是操作表的
而DML是操作数据的
DML【数据修改语句】
向表中插入数据(insert)
单行插入

Sno、Sname等字段可以不写,如果不写的话就默认为数据为空(前提是该字段允许为空,或已设置defalut值)
如果字段名全部省略,就默认为所有的数据都要填上,所有数据都要填充,且要按照表中字段顺序填入


多行指定列插入

同单行插入一样,字段名可以省略(但是数据插入要按字段顺序);
部分字段名可以不写,默认为空(前提是该字段允许为空,或者有default值)
插入否则更新(on duplicate update)
如果要插入的数据,其主键或唯一键,与表中现存数据重合,则插入数据失败。此时我们可以选择更新现有数据。
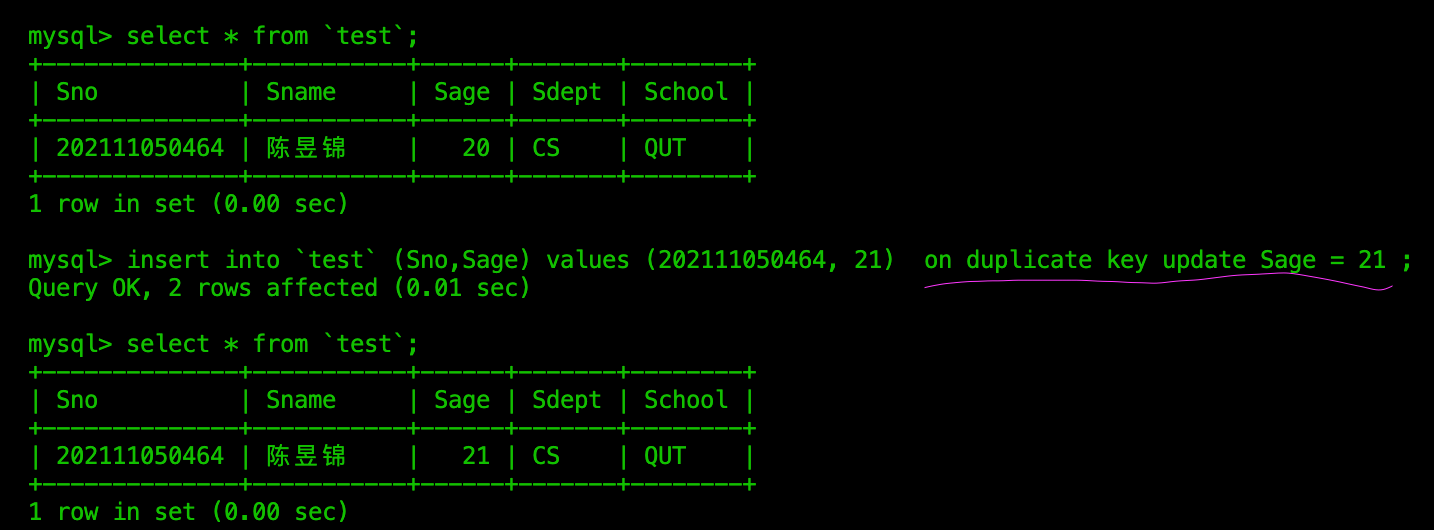
在test表中插入数据Sno、Sage(Sno必填,因为是主键),如果填入的内容与主键发生重复冲突,则更新
update语句后面指定字段中的内容示例中是,如果发生主键/唯一键冲突,则将该主键/唯一键对应的数据中Sno字段数据改为21
插入否则替换(replace)
与更新update不同,更新是只更新数据中原有的部分字段,替换replace则是先删除原数据(所有字段),然后根据要填入的value再插入。
要插入的数据的主键/唯一键与现有数据冲突时,replace将现有数据所有字段删除,将要插入的数据重新插入。即replace在遇到冲突时,是先删除,后插入。

- replace在无冲突时,相当于普通的insert
- replace在冲突时,将原有数据删除后,原有数据不保留,只会插入replace语句中表明要插入的values
- 与insert一样,允许省略全部字段名,或者省略部分允许为空或已设定好default值的字段名
从这里可以看出,数据是先删除后插入

查看表中的数据
基本写法
1 | SELECT |
全列查询
*为通配符
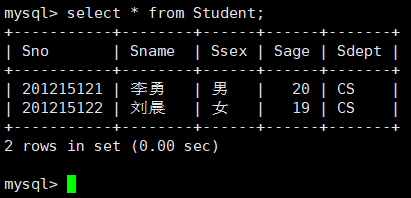
查看Student所有数据:
查看Course所有数据:
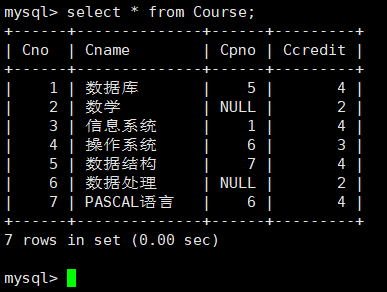
- NULL表示没有数据,和’’不同,’’是有数据,数据是空字符串。
- 一般情况下不建议使用全列查询
- 查询到的数据越多,数据传输量越大
- 可能会影响索引的使用
按列查询
查询指定字段的数据,并汇聚成一张表呈现出来

表达式查询
所以可以看出来,select到from之间的这部分,实际上就是规定了查询结果的字段。而MySQL支持将查询结果通过表达式进行展示
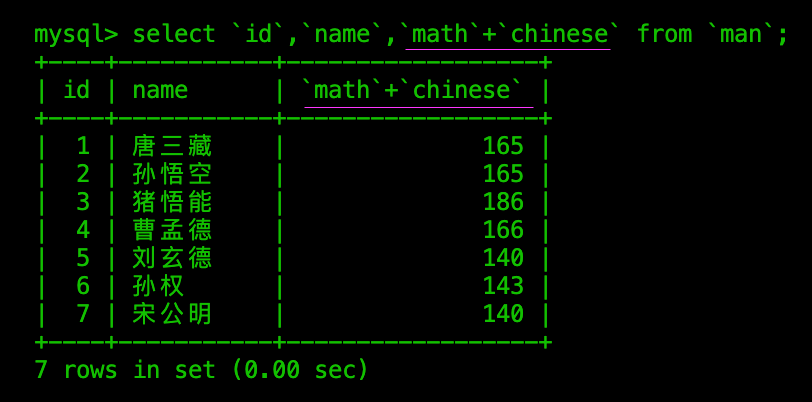
为表达式查询结果设置别名
这样可以增强查询结果的可读性

查询结果去重(select distinct)
有些使用场景下可能需要用到去重,比如上面,只是想知道总体上都是有哪几种总分,因此可以对结果进行去重。

注意去重只是去掉所有字段都重复的数据,所以结果中,就算有一个字段存在重复的数据,但是其他字段不重复,该数据也不会被去掉

条件查询(where)【重要】
基本用法就是在表名后加where,后面是查询条件
where语句支持比较运算符和逻辑运算符
| 比较运算符 | 说明 |
|---|---|
>, >=, <, <= | |
= | 等于,NULL 不安全,NULL=NULL 的结果是 NULL |
<=> | 等于,NULL 安全,NULL<=>NULL 的结果是 TRUE(1) |
!=, <> | 不等于 |
BETWEEN a AND b | 范围匹配,闭区间,如果 a <= value <= b 返回 TRUE(1) |
IN (option, ..., ...) | 如果是 option 中的任意一个,则返回 TRUE(1) |
IS NULL | 是 NULL |
IS NOT NULL | 不是 NULL |
LIKE | 模糊匹配,% 表示任意多个(包括 0 个)字符;_表示任意一个字符; |
| 逻辑运算符 | 说明 |
|---|---|
| AND | 与,相当于 cpp 中的 &&,全真为 1,有假为 0 |
| OR | 或,相当于 cpp 中的 ` |
| NOT | 逻辑取反,条件为 TRUE(1) 的时候结果为 FALSE(0) |
使用比较和逻辑运算符:

使用BETWEEN…AND…进行区间筛选:

配合逻辑运算符,使用相等筛选:

使用IN也可以实现相同效果:

使用LIKE进行字符匹配:
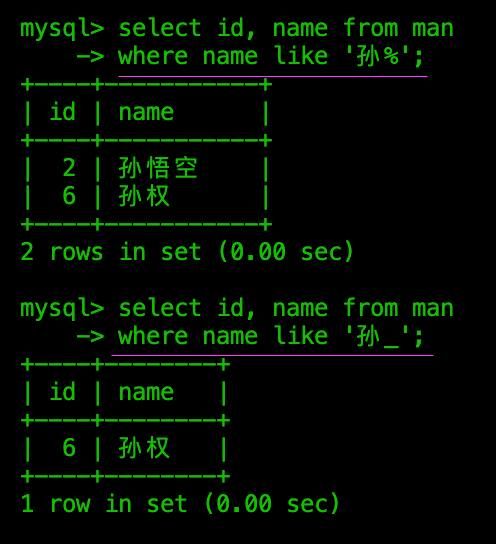
计算后筛选&设置别名:
需要注意的是,where只是进行条件筛选,起别名的工作并不是通过where语句完成的,而是select本身
并且起别名本质是在表示结果的时候更换一下结果表的字段名,并不影响查询过程,所以where是不认识别名的

使用IS NULL 或者 IS NOT NULL查询:
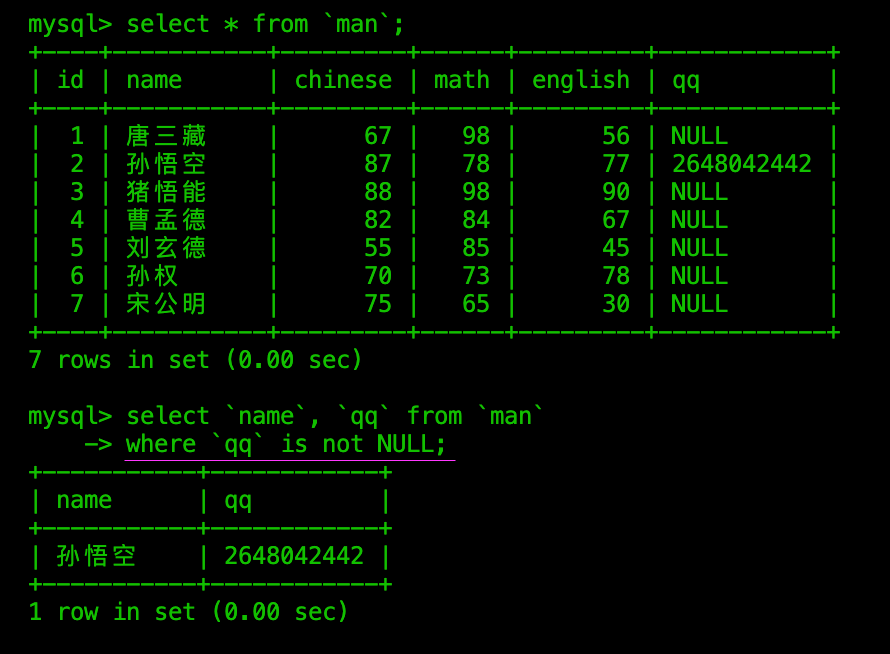
where查询条件不一定必须存在于select要查询的字段中:
使用where时设置条件的字段,可以与select查询要获取的结果集字段无关,而是可以根据原有表中任意字段进行筛选

结果排序(order by)
按单字段升序【默认】/ 降序【后加DESC】 显示
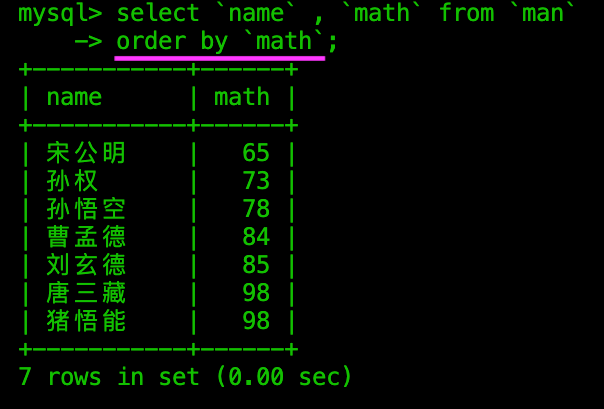
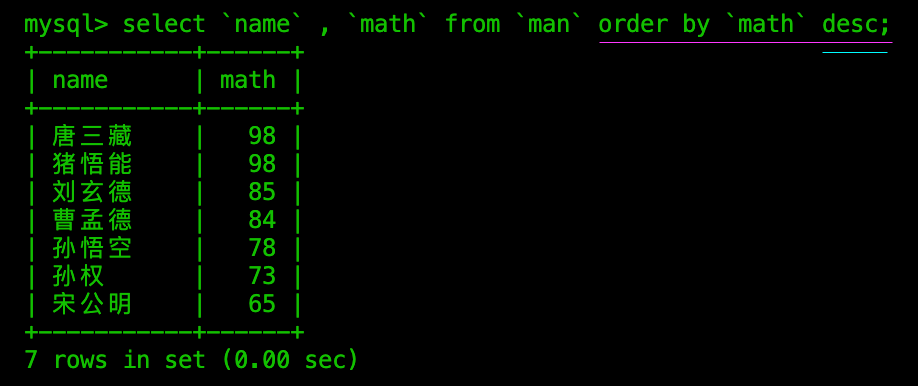
降序在字段后加EDSC
按多字段排序
按照书写先后确定排序优先级

先按照数学将序排序,相等时,就再参考语文的升序,如果还是相等,参考英语的升序
按求和结果排序

排序的时候可以使用别名,说明排序只是对于查询后的结果表进行排序,而不同于where(在查询时按条件筛选)
where + order by

查询语文成绩大于70分的学生的id、姓名、数学成绩
并将查询结果按照语文成绩,降序排列
- where查询条件不一定必须存在于select要查询的字段中,而是可以根据原有表中任意字段进行筛选
- 排序也不一定按照select查询结果的字段进行排序,而是可以按照原有表中任意字段排序
 wechat
wechat